使用Ollama 部署 本地 Deepseek R1大模型 - 全文内容:
显示技术博客列表使用Ollama 部署 本地 Deepseek R1大模型
超短链接
电脑系统与硬件要求:
电脑系统Windows 10及以上版本。
1. DeepSeek-R1:7B / 8B(70亿/80亿参数)
内存(RAM):
最低:16GB(纯CPU运行,但速度较慢)
推荐:32GB(流畅运行)
显存(GPU):
最低:8GB(如NVIDIA RTX 3060/3070)可加载量化版(如4-bit量化)。
推荐:12GB+(如RTX 3080/4080)运行原生模型更流畅。
存储:至少10GB空间(模型文件约5-8GB)。
CPU:4核以上(若依赖CPU推理)。
2. DeepSeek-R1:14B(140亿参数)
内存(RAM):
最低:32GB(CPU模式可能需更多交换空间)。
推荐:64GB(避免频繁交换)。
显存(GPU):
最低:16GB(如RTX 4090)运行量化版。
推荐:24GB+(如A5000/A6000)运行原生模型。
存储:20GB+空间(模型文件约15GB)。
CPU:8核以上(CPU推理需求较高)。
3. DeepSeek-R1:32B(320亿参数)
内存(RAM):
最低:64GB(CPU模式极慢)。
推荐:128GB+(GPU模式需大内存支持)。
显存(GPU):
最低:2x24GB(如双A6000/A100,需模型并行)。
推荐:4x24GB或单卡80GB(如A100 80GB)。
存储:50GB+空间(模型文件约30-40GB)。
CPU:16核以上(多线程/分布式支持)。
4. DeepSeek-R1:70B(700亿参数)
内存(RAM):
最低:128GB(仅CPU几乎不可行)。
推荐:256GB+(分布式GPU必需)。
显存(GPU):
必须多卡:4x A100 80GB 或 8x RTX 4090(通过模型并行+量化)。
企业级硬件(如H100集群)更佳。
存储:100GB+空间(模型文件约70-80GB)。
CPU:32核以上(协调多GPU通信)。
通用建议
量化模型:
使用4-bit/8-bit量化可显著降低显存需求(如70B量化后可在单卡24GB显存运行,但精度下降)。
GPU vs CPU:
CPU推理仅适合小模型(7B/8B),且速度可能慢10-100倍。
多GPU支持:
大模型(32B+)需
NVLink或高速PCIe互联以减少通信开销。
Ollama优化:
Ollama会尝试自动选择最佳运行方式(如优先GPU),但需硬件支持。
参考配置示例
| 模型规模 | 消费级硬件 | 专业级硬件 |
|---|---|---|
| 7B/8B | RTX 3060 + 32GB RAM | RTX 4090 + 64GB RAM |
| 14B | RTX 4090 + 64GB RAM | A6000 x2 + 128GB RAM |
| 32B | 不推荐消费级 | A100 x2 + 256GB RAM |
| 70B | 无法运行 | H100集群 + 512GB RAM |
如需具体测试,建议从7B开始逐步验证硬件兼容性。
Ollama 下载安装:
1、从官网进入点击对应的系统下载安装程序(大概1GB多):

2、安装时通过命令指定安装目录:
D:\>OllamaSetup.exe /DIR="D:\Ollama"
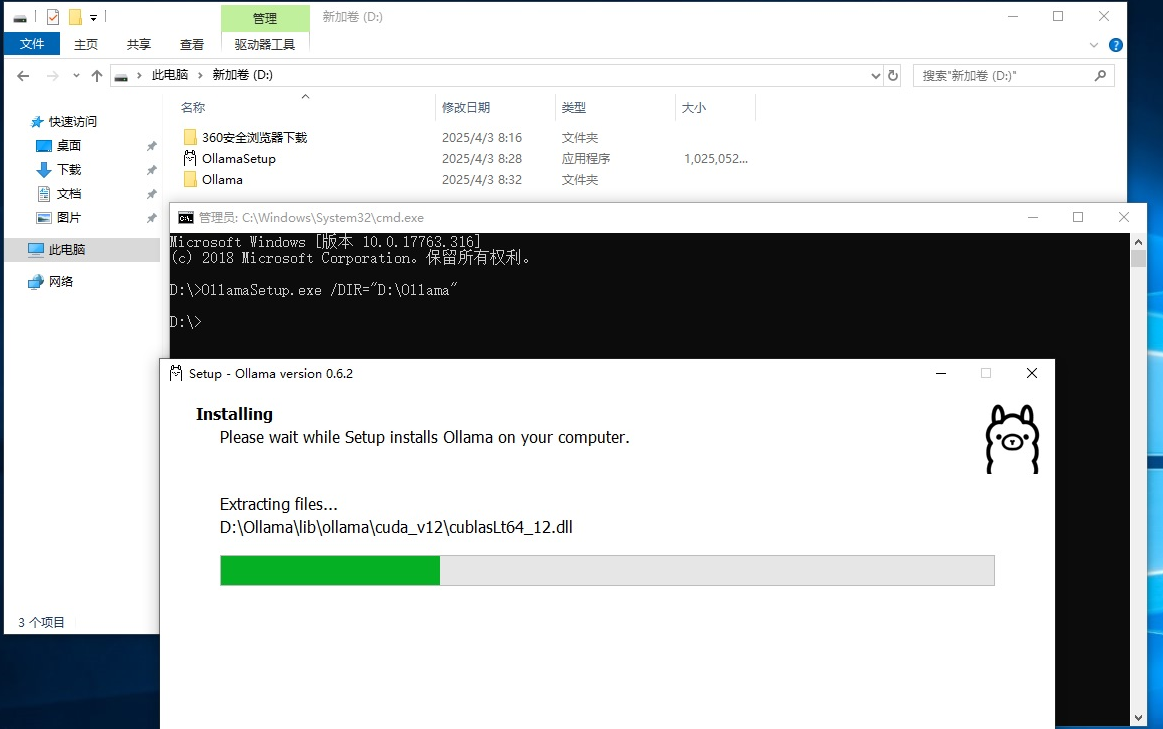
3、更改模型下载的默认路径:
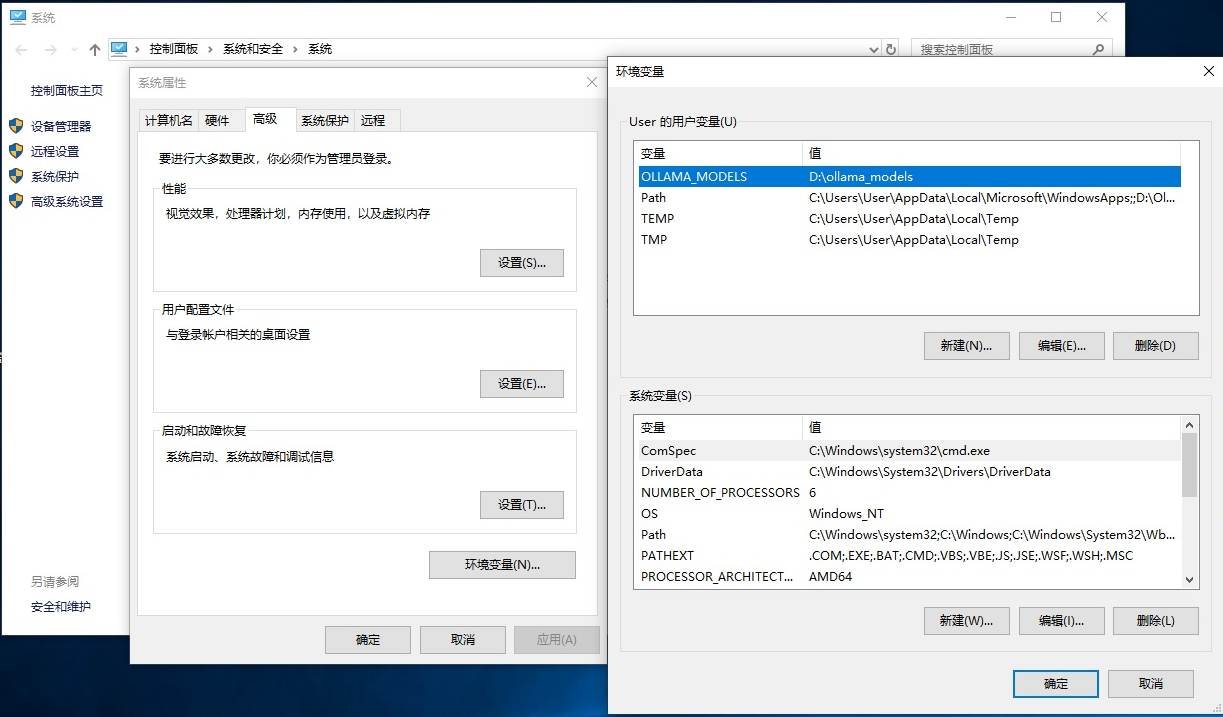
按 Win + R,输入 sysdm.cpl (或者右击 桌面 上的 此电脑 图标的 属性),打开 系统属性->切换到 高级 选项卡,点击 环境变量 -> 在 用户变量 或 系统变量 中,点击 新建 -> 变量名:OLLAMA_MODELS ->变量值:D:\ollama_models(或你想要的路径)-> 点击 确定 保存 ->重启电脑使设置生效。
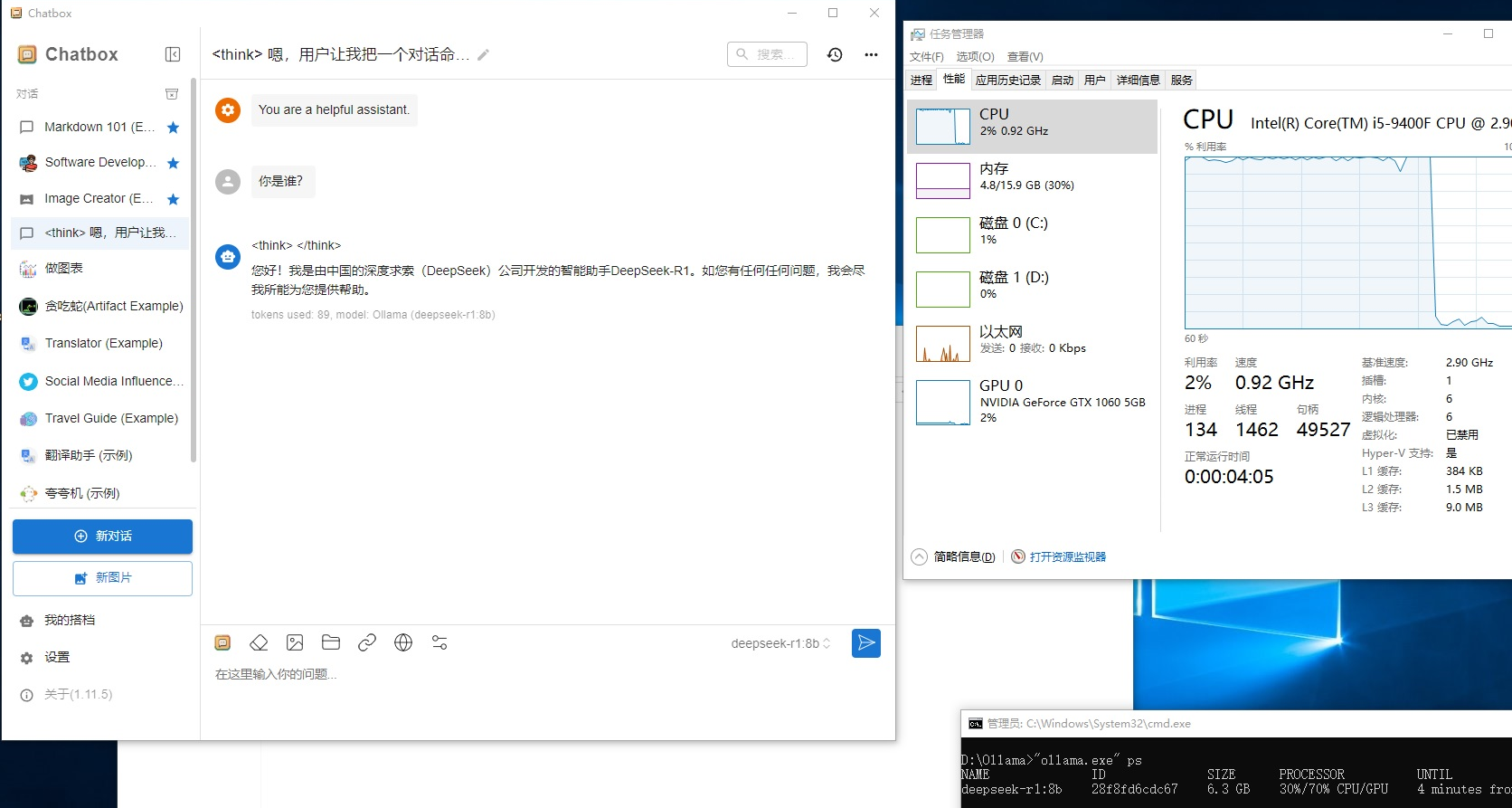
Deekseek R1大模型下载:
官网命令: https://ollama.com/library/deepseek-r1
D:\Ollama>ollama.exe list NAME ID SIZE MODIFIED D:\Ollama>ollama run deepseek-r1:8b pulling manifest pulling 0cb05c6e4e02... 100% ▕████████████████████████████████████████████ ████████████▏ 487 B verifying sha256 digest writing manifest success >>> 你是谁? <think> </think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。 >>> Send a message (/? for help
注意:如下下载速度掉下来了,就按Ctrl+c 终止程序,重新执行以上的命令下载,支持断点续传。
DeepSeek-R1 8B可能的用途:
DeepSeek-R1 8B的实际表现
设计目标:
该模型针对效率与性能平衡优化,适合消费级硬件(如单卡GPU)。优势场景:
日常问答、文本摘要、简单编程辅助等。
比更大模型(如32B)响应更快、资源需求更低。
弱点:
多步数学推理、专业领域知识可能不精准。
eepSeek-R1 7B 和 8B 同属中小规模语言模型,主要面向消费级硬件优化,但两者在参数规模、性能表现和适用场景上存在细微差异。以下是详细对比:
1. 核心差异
| 特性 | DeepSeek-R1 7B | DeepSeek-R1 8B |
|---|---|---|
| 参数量 | 70亿参数 | 80亿参数 |
| 设计目标 | 极致轻量化,低硬件需求 | 平衡性能与效率,小幅提升能力 |
| 显存需求 | 原生模型:~14GB 4-bit量化:~6GB | 原生模型:~16GB 4-bit量化:~7GB |
| 训练数据 | 约2-3T tokens(推测) | 可能略多于7B(数据分布更优) |
| 推理速度 | 略快(参数更少) | 稍慢但生成质量更稳定 |
2. 性能表现对比
(1)通用任务(聊天、问答)
7B:响应更快,适合实时交互,但复杂问题易出现简短或模糊回答。
8B:生成文本更连贯,对长问题(如“解释量子力学基础”)的回复更详细。
(2)逻辑与推理
7B:能处理简单逻辑(如两步数学题),但错误率较高。
8B:在3-4步推理(如“小明比小红高,小红比小兰高,谁最矮?”)上表现更可靠。
(3)编程能力
7B:可写基础代码(如Python函数),但复杂算法易出错。
8B:能更好理解上下文(如修复代码漏洞),适合辅助调试。
(4)多语言支持
两者均以中文和英语为主,8B在小语种(如法语、西班牙语)的翻译任务上略优。
3. 硬件适配性
| 硬件 | 7B推荐配置 | 8B推荐配置 |
|---|---|---|
| GPU | RTX 3060(8GB显存量化) | RTX 3060 Ti(8GB显存量化) |
| CPU | i5-12400 + 32GB RAM | i5-13400 + 32GB RAM |
| 推理速度 | ~25 tokens/s(RTX 3060) | ~20 tokens/s(RTX 3060) |
💡 提示:8B模型对显存压力稍大,若设备临界(如8GB显存),7B的量化版更稳定。
4. 如何选择?
选7B:
硬件有限(如轻薄本、低配GPU)
需要极致响应速度(如实时聊天机器人)
选8B:
追求略好的文本质量和逻辑能力
设备有显存余量(如10GB+显存)
对话APP Chatbox AI安装与配置:
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
ChatAIbox 官网: https://chatboxai.app/zh
下载地址: https://chatboxai.app/install_chatbox/win64
设置:
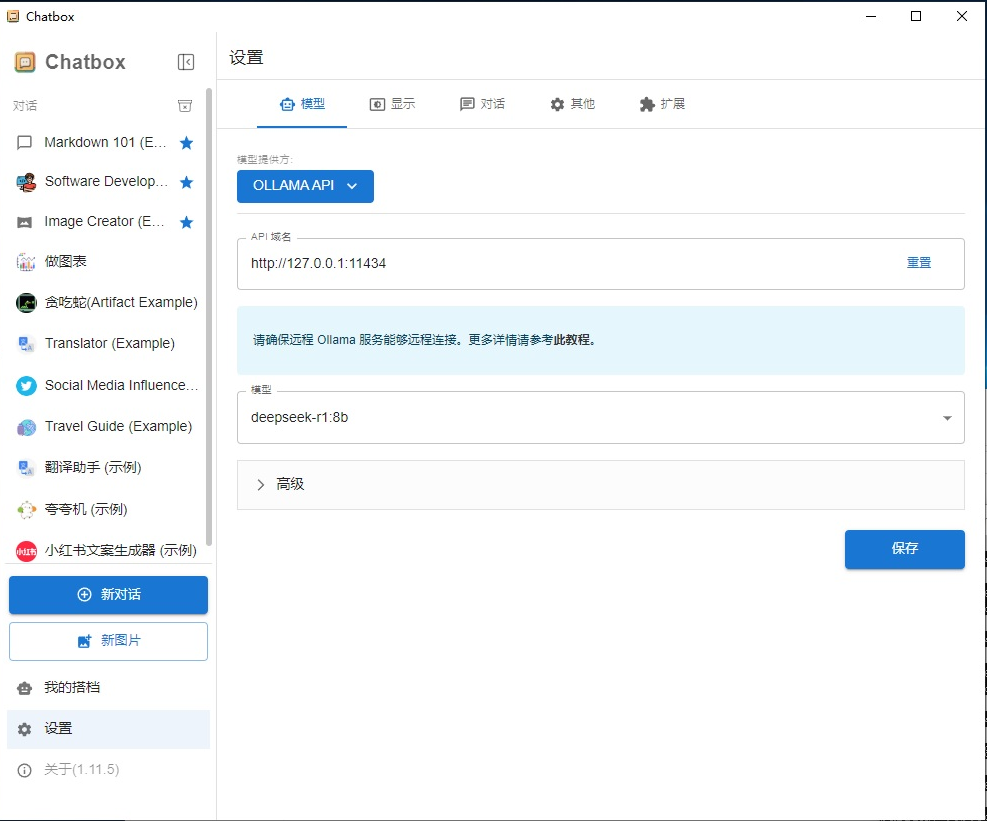
使用: